Aliyun-DRDS介绍
DRDS是aliyun商业版本的TDDL。提供分库分表,读写分离等操作。 类似于Mycat等分库分表中间件。 对应用透明
产品架构
https://help.aliyun.com/document_detail/117771.html
基本操作
-
创建DRDS
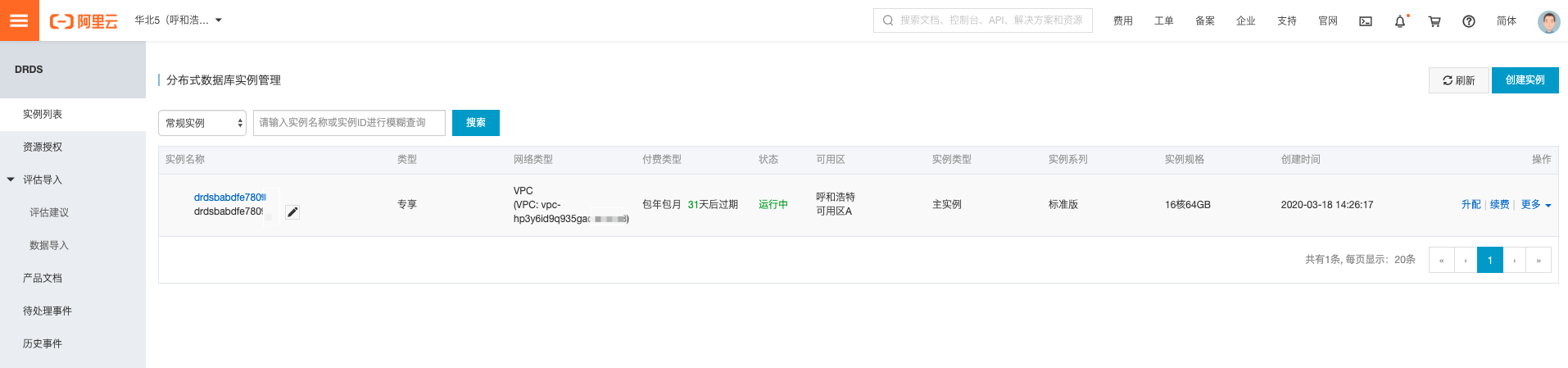
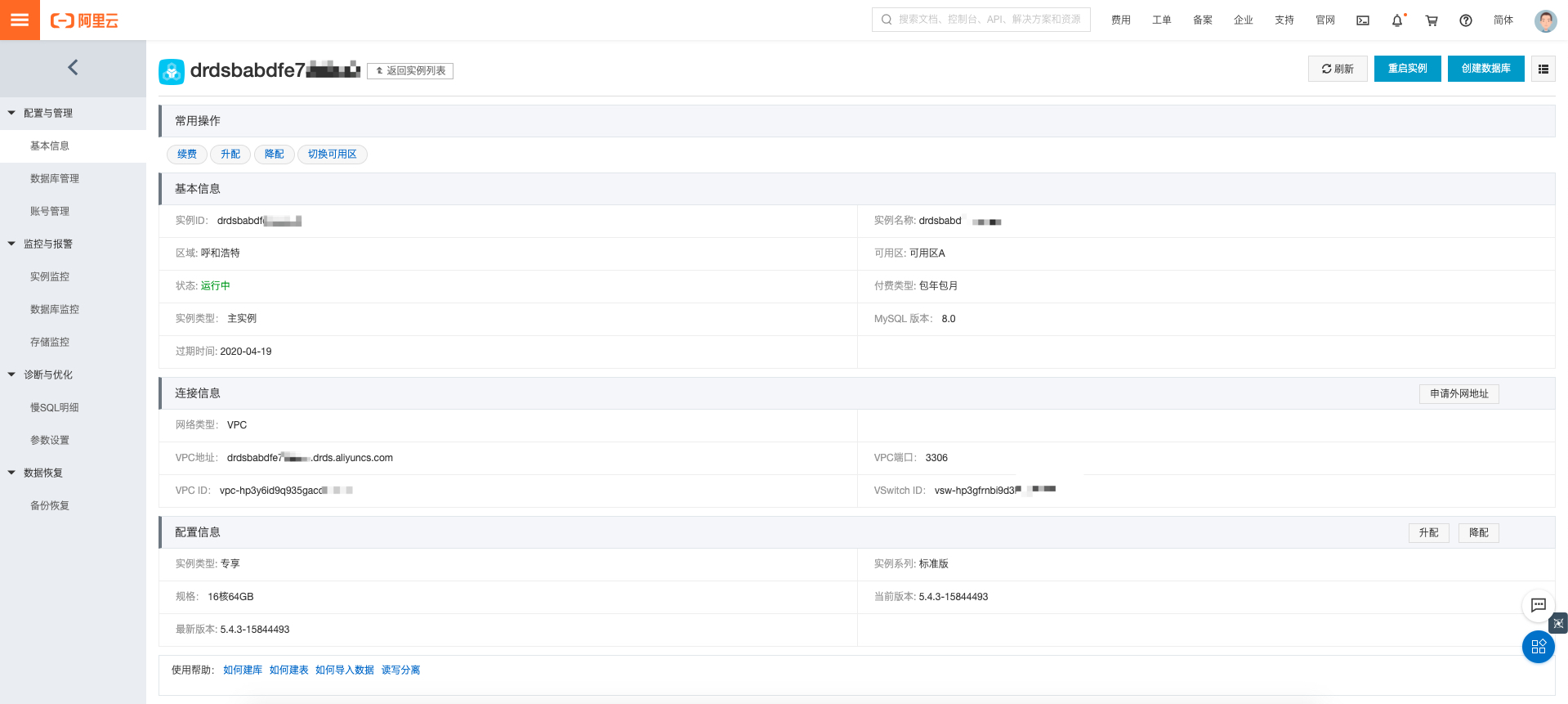
-
创建数据库
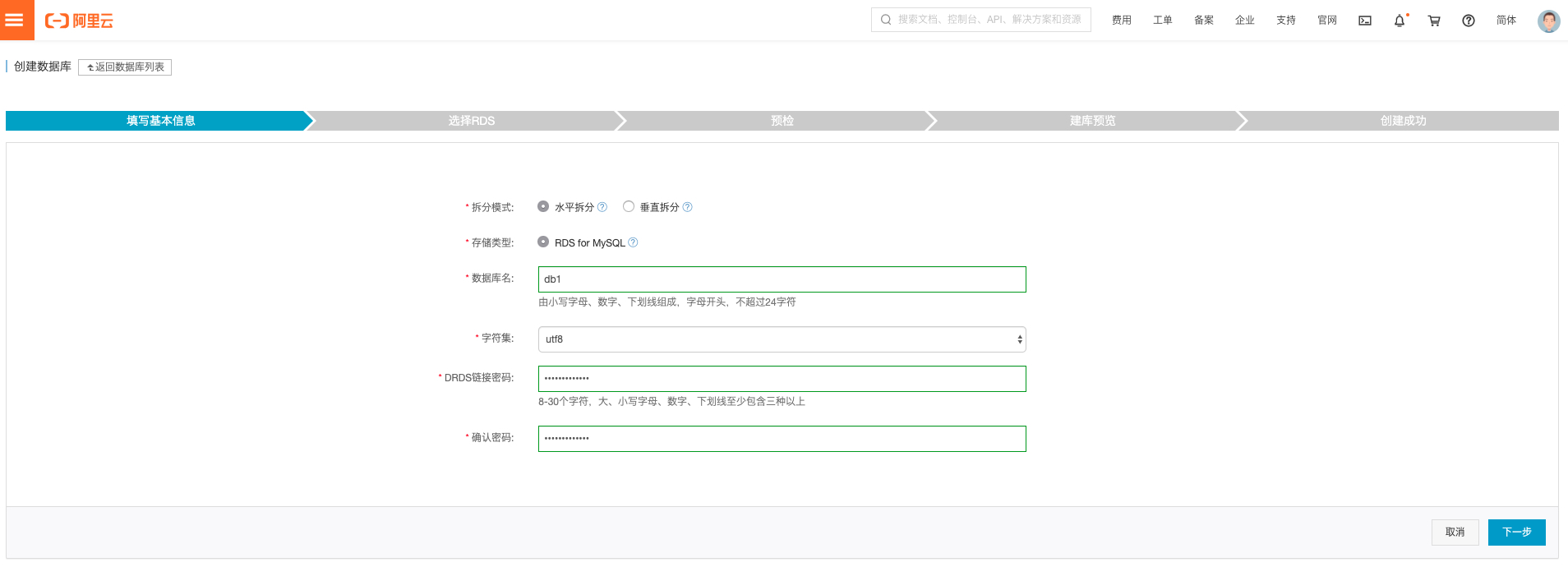
-
挂载RDS实例(DRDS私有实例或者单独购买RDS挂载)
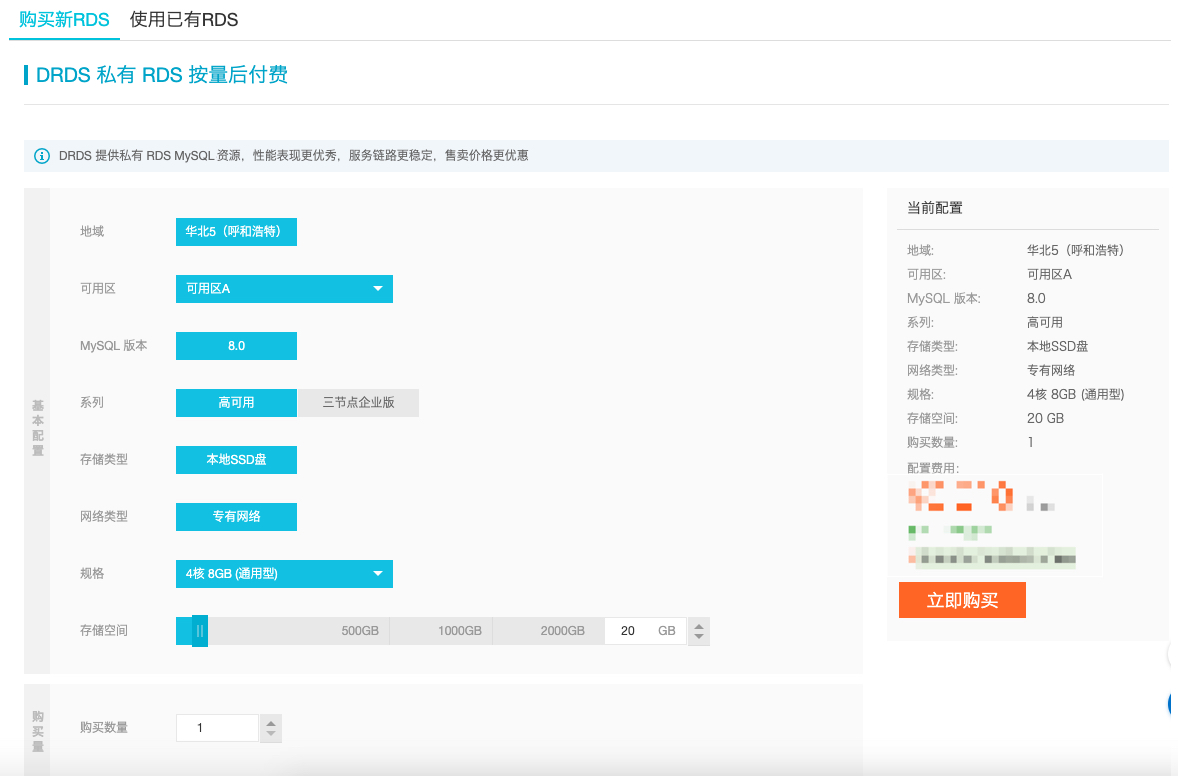
DRDS 扩展性原理
https://help.aliyun.com/document_detail/118010.html
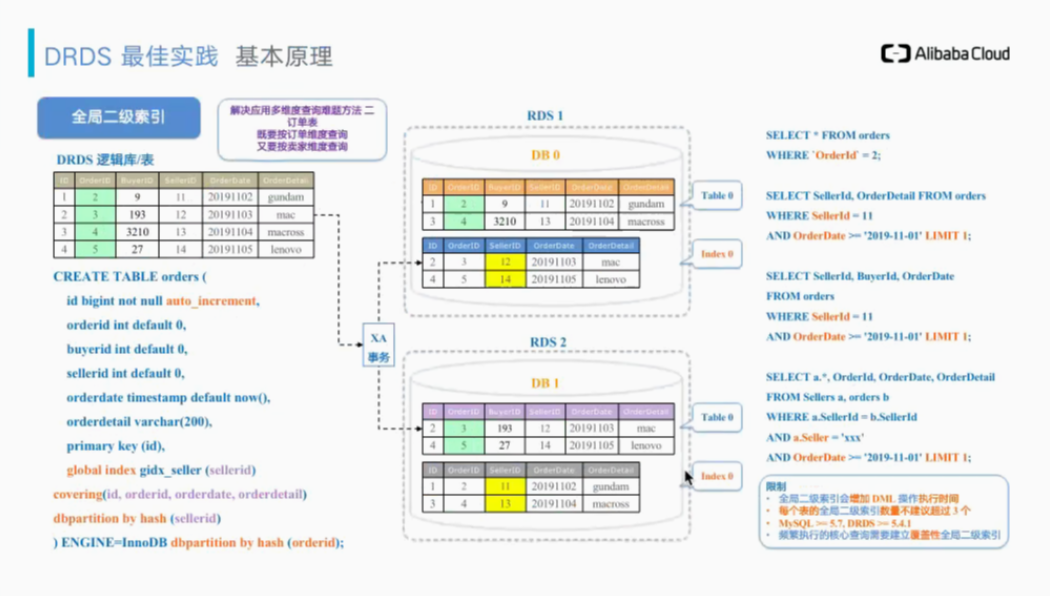
DRDS全局二级索引
https://help.aliyun.com/document_detail/142733.html
全局二级索引使用
DRDS 对 MySQL DDL 语法进行了扩展,增加定义 GSI 的语法。使用方式与在 MySQL 上创建索引一致:
创建二级索引:
|
|
|
|
DRDS自定义语句
DRDS自定义一些特有的语句,用于 帮助用户方便使用DRDS
https://help.aliyun.com/document_detail/29678.html
Sequence介绍
https://help.aliyun.com/document_detail/71261.html?spm=a2c4g.11186623.6.700.6e221ce8j2oPCj
使用场景
这几种 Sequence 都保证全局唯一,均可以应用在主键列和唯一索引列。
- 大部分场景下建议选用 Group Sequence;
- 如果有跨实例或跨库分配全局唯一数字序列的需求,可以选用单元化 Group Sequence;
- 如果业务上能接受整体趋势上的宏观自增,不介意微观上的不保证自增,且不想依赖数据库的分配机制,则 Time-based Sequence 可能是合适的选择;
- 如果业务强依赖连续的 Sequence 值,此时只能使用 Simple Sequence(注意 Simple Sequence 的性能问题)。
以创建一个起始值是 100000,步长为 1 的 Sequence 为例。
- 如果采用 Simple Sequence,则会严格产生
100000、100001、100002、100003、100004、.....、200000、200001、200002、200003、......这样的序列(全局唯一、连续、单调递增)。Simple Sequence 会保证持久化,即使发生单点问题,服务重启后依然会在断点继续产生 Sequence 值,中间不会产生跳跃段。Simple Sequence 的机理是每产生一个值都要进行一次持久化操作,因此性能并不是很好。 - 如果采用 Group Sequence 或 单元化 Group Sequence,产生的序列有可能是
200001、200002、200003、200004、100001、100002、100003、......这样的序列。
注意:
- Group Sequence 起始值并不会严格从设定的参数(本例中是100000)开始,但保证比该参数大。本例中是从 200001 开始取值的。
- Group Sequence 保证全局唯一,但是会有跳跃段。比如 Group Sequence 的某个节点失效,或者某个连接只取了一部分值,然后该连接被关闭了,都会产生跳跃段。该例中 200004 和 100001 之间产生了跳跃段。
- 单元化 Group Sequence 跨实例或跨库的全局唯一性,必须通过指定相同的单元数量和不同的单元索引来保证。
广播表
子句BROADCAST用来指定创建广播表。广播表是指将这个表复制到每个分库上,在分库上通过同步机制实现数据一致,有秒级延迟。这样做的好处是可以将 JOIN 操作下推到底层的 RDS(MySQL),来避免跨库 JOIN。SQL 优化方法 详细讲述了如何使用广播表来做 SQL 优化。
|
|
SQL优化
https://help.aliyun.com/document_detail/144294.html?spm=a2c4g.11186623.6.665.2e196f96JbVRjV
Hint
|
|
https://help.aliyun.com/document_detail/71270.html?spm=a2c4g.11186623.6.735.628d5f76NiqCTU
- 原文作者:Kalend
- 原文链接:https://blog.kalend.top/2022/05/31/aliyun-drds.html
- 版权声明:本作品采用CC BY-NC-SA 4.0进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。


